I was in such a rush to finish Project 3 by Sunday night, I didn’t post about the rest of my results, and now before I got a chance to write about it, the professor has already graded it! I got 100% on this one I just turned in, and also just found out I got 100% on Project 2!! This makes me feel so good, especially since I didn’t do so well on the midterm, and confirms that I can do this! Now there is one final project and that is the last deliverable for this class. I’ll talk about Project 4 in a future post.
So, to wrap up Project 3. I ended up getting the Neural Networks working in PyBrain, but when it came to Support Vector Machines (SVM), I just could not get it to run without errors. I had already downgraded to Python 2.7 to get PyBrain working at all, but there were further dependencies for the SVM functionality, and at midnight the night before it was due, I still hadn’t gotten it to run, so I figured it was time to try another approach. This is when I started looking at SciKit-Learn SVM.
I had wanted to do the whole project in PyBrain if possible, but it turned out that switching to SciKit-Learn (also called sklearn) was a good idea, because the documentation was helpful and the implementation painless. I had to tweak how I was importing the data from the training and test files since I was no longer using PyBrain’s ClassificationDataSet, but that wasn’t a complicated edit.
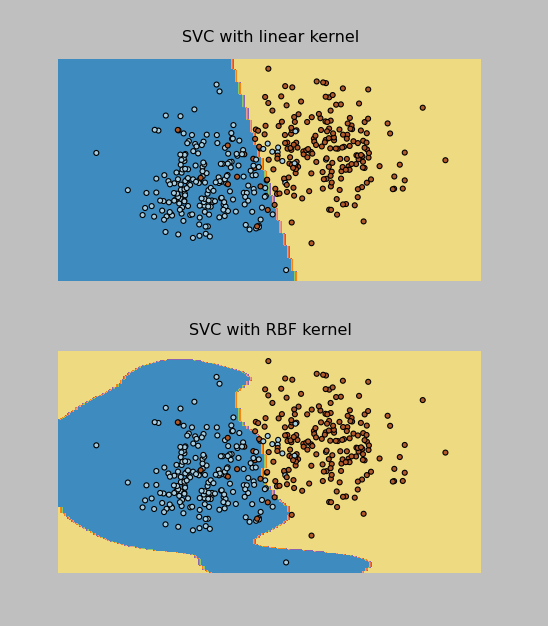
I was able to implement both the RBF and Linear kernel versions of the SVM Classifier (called SVC in sklearn). The Linear one actually worked better on the test data provided by the professor, and it correctly classified 96% of the data points (which were evenly split into 2 classes). In addition, I was able to make these cool plots by following the instructions here.
I have pasted the SVM code below and attached all of my project files to this post. Now on to the Final Project, due May 9.
Thanks to everyone that gave me tips on Twitter while I was working through the installations on this one!
import pylab as pl
import numpy as np
from sklearn import svm, datasets
print("\nImporting training data...")
#bring in data from training file
f = open("classification.tra")
inp = []
tar = []
for line in f.readlines():
inp.append(list(map(float, line.split()))[0:2])
tar.append(int(list(map(float, line.split()))[2])-1)
print("Training rows: %d " % len(inp) )
print("Input dimensions: %d, output dimensions: %d" % ( len(inp), len(tar)))
#raw_input("Press Enter to view training data...")
#print(traindata)
print("\nFirst sample: ", inp[0], tar[0])
#sk-learn SVM
svm_model = svm.SVC(kernel='linear')
svm_model.fit(inp,tar)
#show predictions
out = svm_model.predict(inp)
#print(test)
class_predict = [0.0 for i in range(len(out))]
predict_correct = []
pred_corr_class1 = []
pred_corr_class2 = []
for index, row in enumerate(out):
if row == 0:
class_predict[index] = 0
else:
class_predict[index] = 1
for N in range(len(class_predict)):
if class_predict[N] == tar[N]:
if tar[N] == 0:
pred_corr_class2.append(1)
if tar[N] == 1:
pred_corr_class1.append(1)
predict_correct.append(1)
else:
if tar[N] == 0:
pred_corr_class2.append(0)
if tar[N] == 1:
pred_corr_class1.append(0)
predict_correct.append(0)
print ("SVM Kernel: ", svm_model.kernel)
print ("\nCorrectly classified: %d, Percent: %f, Error: %f" % (sum(predict_correct),sum(predict_correct)/float(len(predict_correct)),1-sum(predict_correct)/float(len(predict_correct))))
print ("Class 1 correct: %d, Percent: %f, Error: %f" % (sum(pred_corr_class1),sum(pred_corr_class1)/float(len(pred_corr_class1)),1-sum(pred_corr_class1)/float(len(pred_corr_class1))))
print ("Class 2 correct: %d, Percent: %f, Error: %f" % (sum(pred_corr_class2),sum(pred_corr_class2)/float(len(pred_corr_class2)),1-sum(pred_corr_class2)/float(len(pred_corr_class2))))
raw_input("\nPress Enter to start testing...")
print("\nImporting testing data...")
#bring in data from testing file
f = open("classification.tst")
inp_tst = []
tar_tst = []
for line in f.readlines():
inp_tst.append(list(map(float, line.split()))[0:2])
tar_tst.append(int(list(map(float, line.split()))[2])-1)
print("Testing rows: %d " % len(inp_tst) )
print("Input dimensions: %d, output dimensions: %d" % ( len(inp_tst), len(tar_tst)))
print("\nFirst sample: ", inp_tst[0], tar_tst[0])
print("\nTesting...")
#show predictions
out_tst = svm_model.predict(inp_tst)
#print(test)
class_predict = [0.0 for i in range(len(out_tst))]
predict_correct = []
pred_corr_class1 = []
pred_corr_class2 = []
for index, row in enumerate(out_tst):
if row == 0:
class_predict[index] = 0
else:
class_predict[index] = 1
for N in range(len(class_predict)):
if class_predict[N] == tar_tst[N]:
if tar_tst[N] == 0:
pred_corr_class2.append(1)
if tar_tst[N] == 1:
pred_corr_class1.append(1)
predict_correct.append(1)
else:
if tar_tst[N] == 0:
pred_corr_class2.append(0)
if tar_tst[N] == 1:
pred_corr_class1.append(0)
predict_correct.append(0)
print ("\nTest Data Correctly classified: %d, Percent: %f, Error: %f" % (sum(predict_correct),sum(predict_correct)/float(len(predict_correct)),1-sum(predict_correct)/float(len(predict_correct))))
print ("Class 1 correct: %d, Percent: %f, Error: %f" % (sum(pred_corr_class1),sum(pred_corr_class1)/float(len(pred_corr_class1)),1-sum(pred_corr_class1)/float(len(pred_corr_class1))))
print ("Class 2 correct: %d, Percent: %f, Error: %f" % (sum(pred_corr_class2),sum(pred_corr_class2)/float(len(pred_corr_class2)),1-sum(pred_corr_class2)/float(len(pred_corr_class2))))
(I had to change the .py files to .txt in order for WordPress to upload them. The “zips” files are for the data sets that had 16 inputs and 10 classes.)
PyBrain_NeuralNet
PyBrain_NNClassification_zips
PyBrain_NNClassification2
SciKitLearn_SVM
SciKitLearn_SVM_zips